Data mining
I begynnelsen av kapittelet snakket vi om å grave etter gull. Det er ikke så langt fra sannheten! Graving, eller rettere sagt mining, er en stor del av prosessen bak det å gjøre data verdifullt.
Vi har sett på databaser, statistikk og maskinlæring. I skjæringspunktet mellom alle disse finner vi altså data mining (eller datautvinning som det heter på norsk).
Innsikt
Data mining eller datautvinning?
Når det gjelder uttrykket datautvinning, er det flere som vil si at det ikke er en god oversettelse av data mining. Utvinning er en del av prosessen, men er ikke beskrivende for alle teknikker og fremgangsmåter som inngår under data mining. Datautvinning blir ofte brukt i norsk faglitteratur, men her holder vi oss altså til det engelske begrepet.
Data mining er en teknikk som brukes for å automatisk analysere store datasett for å se etter mønstre og for å oppdage ukjente egenskaper i et sett med data. Teknikken kan brukes til alt fra å gjøre markedsanalyser for å identifisere nye produktgrupper, forutsi fremtidige trender eller for å avdekke sikkerhetsbrister i et nettverk.
Man kan definere data mining som prosessen bak det å trekke ut (utvinne) informasjon fra et datasett, for så å transformere det til en forståelig struktur for videre bruk.
Det sier seg kanskje selv at data mining ikke er noe som gjøres manuelt. Her benytter vi oss av automatiserte prosesser.
I noen tilfeller automatiseres data mining ved hjelp av maskinlæring, for eksempel i møte med ustrukturerte data. I andre tilfeller gjøres jobben ved hjelp av programvarer som med trinnvise instrukser og ikke-intelligente algoritmer gis beskjed om hva de skal lete etter.
Vi skal snart se nærmere på teknikkene vi bruker under data mining. Her er det viktig å påpeke at disse ofte overlapper, og at man nesten alltid kombinerer to eller flere teknikker for å komme seg til mål.
Det finnes altså en rekke teknikker knyttet til data mining. De vi skal se på her er disse:
- Assosiasjon / relasjonsteknikker (association / relationship)
- Klassifisering (classification)
- Gruppering (clustering)
- Prediksjon (prediction)
- Beslutningstrær (decision trees)
- Tekst-mining
- Sosiale nettverk-analyse (SNA)
- Prosess-mining
Det ser kanskje litt komplisert ut, men er faktisk enklere å forstå enn man skulle tro! La oss starte fra toppen:
Assosiasjon / relasjonsteknikker
Assosiasjoner (også kalt for relasjonsteknikker) handler om å identifisere sammenhenger mellom variabler: Hvis vi ser A, kan vi forvente å se B.
Vi kan forstå hvordan assosiasjonsteknikk fungerer ved å tenke oss hvordan en lege ville stilt en diagnose. Først kartlegger hun symptomer: Hvilke beslektede sykdommer kan legen ta med i beregningen, og hvilke kan hun avkrefte? Assosiasjon er tett knyttet til statistiske prinsipper som sannsynlighet.
Et annet eksempel er dette: Mange kunder i en nettbutikk har kjøpt seg en bærbar datamaskin. De samme kundene har også kjøpt seg en trådløs mus. Da vil assoiasjonsteknikken avdekke et forhold mellom variabelen bærbar datamaskin og variabelen trådløs mus – to sett med data som ikke hadde slektskap som rene datapunkter. Med denne informasjonen kan nettbutikken tilby pakketilbud med datamaskinen og musen.
Dette er eksempler som en kunne tenkt seg selv. Men ved hjelp av data mining-teknikker kan vi finne assosiasjoner og relasjoner som er mye mindre åpenbare. Kanskje vi eksempelvis finner hittil ukjente sammenhenger mellom sykdom og symptomer, som lar oss starte tidligere behandling.
Klassifisering
Klassifisering har vi allerede snakket om i forbindelse med maskinlæring. Det dreier seg altså om å sortere data i forhåndsdefinerte klasser. Dette gir oss både en måte å forstå dataene på og å skille mellom dem.
Selv om maskinlæring ofte brukes til dette, kan det også gjøres med regelbaserte systemer, som for eksempel ser etter bestemte stikkord, størrelser eller egenskaper for å klassifisere dataene.
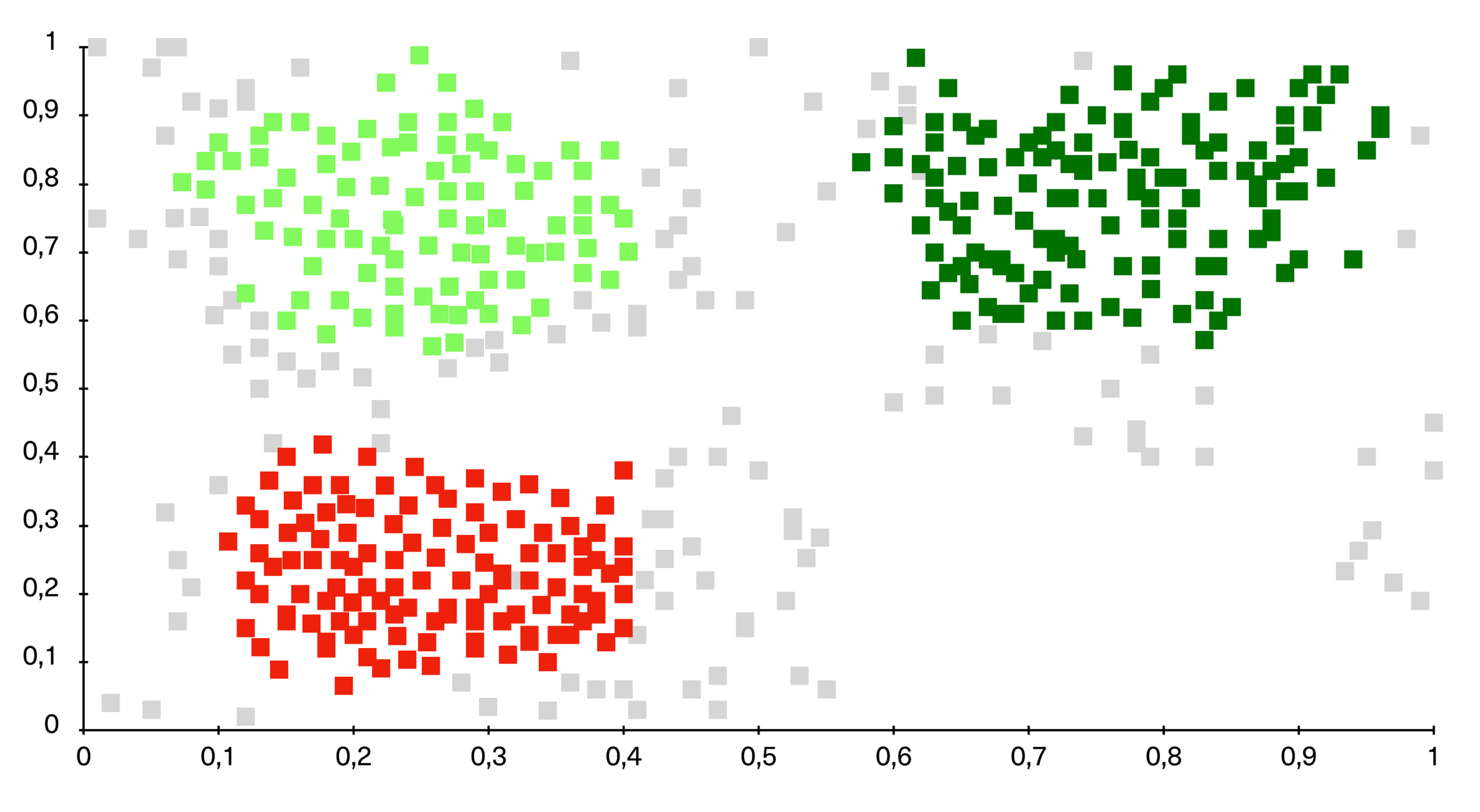
Gruppering
Gruppering (kalt clustering på engelsk) handler om å bruke en eller flere attributter som grunnlag for å identifisere en klynge med korrelerende resultater.
I en klynge er altså alle objektene relatert til hverandre.
Klynger er nyttige for å identifisere forskjellig informasjon fordi det korrelerer med andre eksempler – slik at du kan se hvor likhetene og områdene stemmer overens.
Prediksjon
Prediksjon kan innebære analyse av trender, klassifisering, mønstermatching og relasjoner (av tidligere hendelser) for å forutsi en fremtidig hendelse. For eksempel for å forutsi hvor mye penger en kunde vil bruke, basert på deres inntekt og yrke. Hvis vi har informasjon om tidligere kunder, og ser hvordan disse oppførte seg, kan vi gjøre en prediksjon om en ny kunde hvis vi kjenner deres inntekt og yrke.
Beslutningstrær
Beslutningstrær brukes enten som en del av utvalgskriteriene eller for å støtte bruk og utvelgelse av spesifikke data innenfor den overordnede strukturen.
Ofte starter vi med et enkelt spørsmål – for eksempel: regner det? – som har to eller flere svar. Hvert svar fører til et ytterligere spørsmål for å hjelpe med å klassifisere eller identifisere dataene slik at de kan kategoriseres, eller slik at en prediksjon kan gjøres basert på hvert svar.
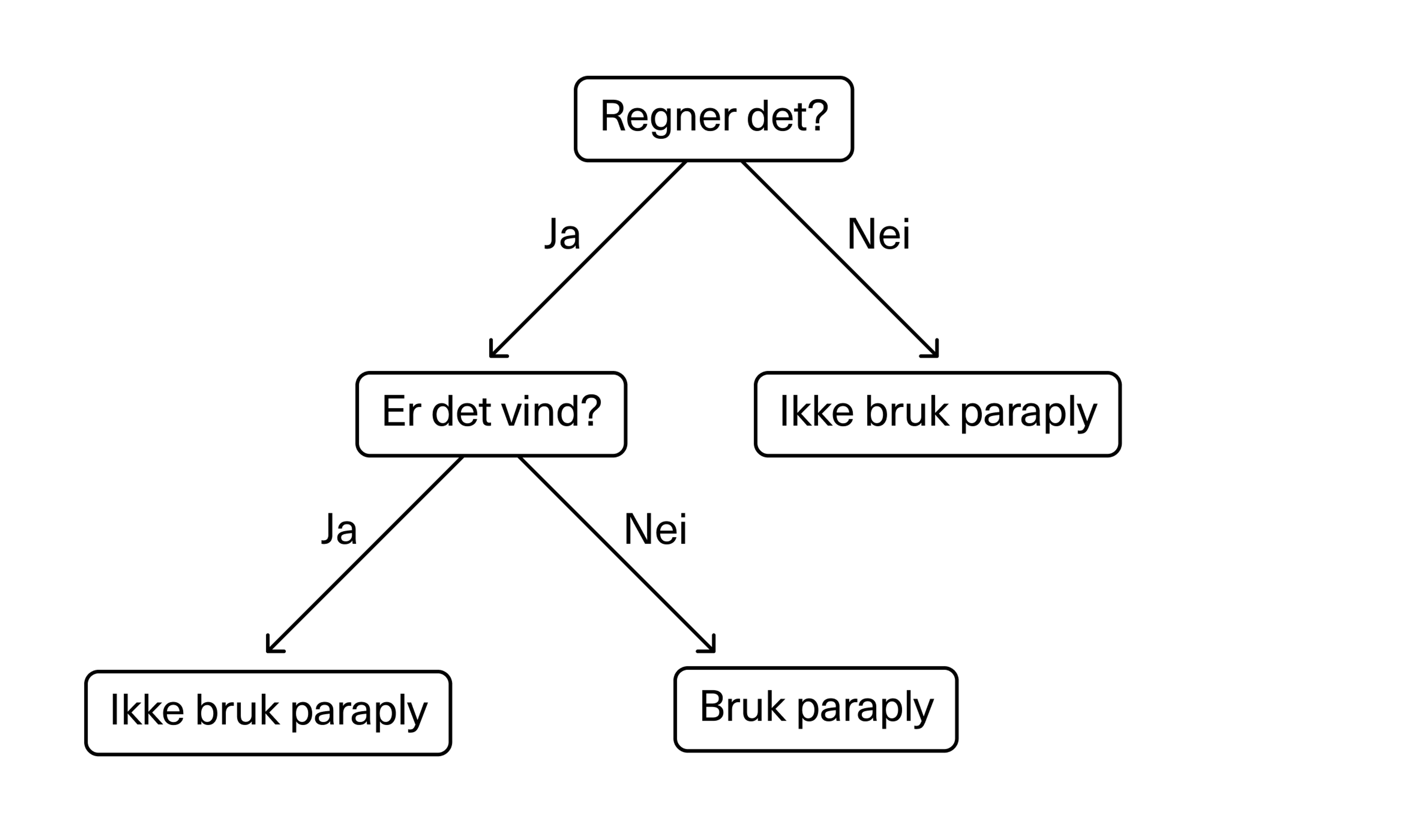
Her er et eksempel som passer bra når du er i Bergen. Første spørsmål er om det regner. Hvis nei, kan vi ta en beslutning om at vi ikke bruker paraply. Hvis ja, kan vi gå videre til neste spørsmål: Er det vind? Hvis nei, kan vi bruke paraply. Hvis ja, vil vi kanskje ikke bruke paraply – da den vil vrenges og bli ødelagt i vinden.
Tekst-mining
Neste metode er «tekst-mining». Det går ut på å undersøke store mengder tekst – for eksempel et utvalg med forskningslitteratur – på jakt etter innsikter om språket og innholdet.
Et enkelt eksempel på dette er en ordsky, eller word cloud på engelsk. Her kan en bruke verktøy som ser på for eksempel et sett med forskningsartikler, og ser hvilke ord som er mye brukt – for så å visualisere disse i en «sky» der ord blir større og tydeligere dess oftere de brukes i teksten.
Det kan si oss noe om hva disse artiklene handler om, hva som er viktig for artikkelforfatterne å få frem og hva slags språk som er brukt. I verktøyene som brukes for å lage slike ordskyer kan du velge å ta ut for eksempel små ord som en, i, på og så videre, som ikke har noen betydning.

Sosiale nettverk-analyse (SNA)
Med sosiale nettverk-analyse (SNA) søker vi å forstå et fellesskap ved å kartlegge relasjonene som forbinder fellesskapets individer som et nettverk – og deretter prøve å trekke frem nøkkelindivider, grupper innenfor nettverket og/eller assosiasjoner mellom individer.
Her har vi et enkelt eksempel hvor du ser representasjoner av ulike individer og hvordan de er knyttet til hverandre.
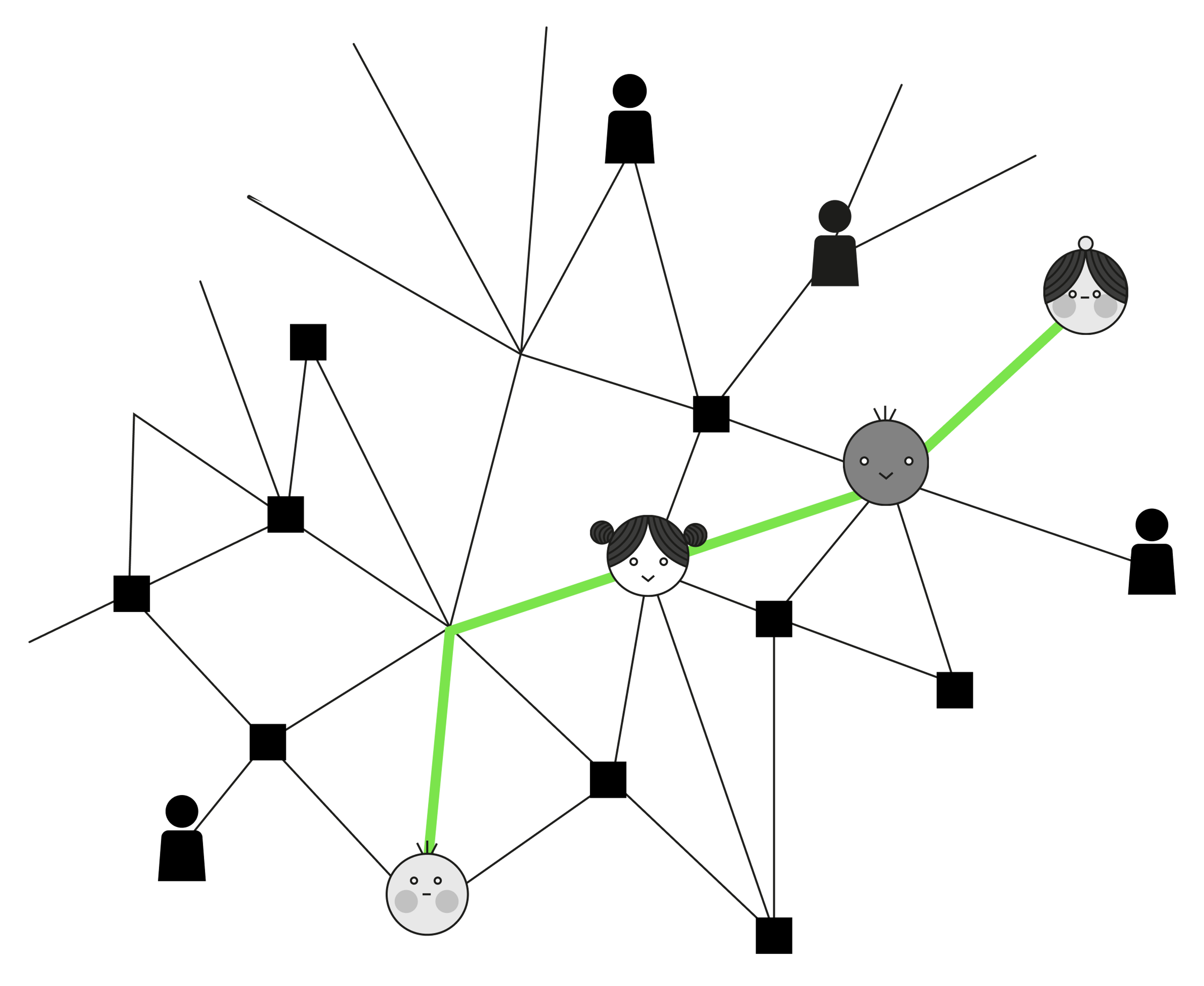
I et mer komplekst nettverk vil en bruke virkemidler som ulik farge og størrelse på nodene (knutepunktene) og linjene for å gjøre de ulike relasjonene mest mulig tydelige.
Nettverksanalyse kan også brukes til å se relasjoner mellom andre typer noder – for eksempel tema i et diskusjonsforum, som i illustrasjonen over. Nodene som er litt større er temaene som er mest diskutert. De kan gis ulike farger etter type tema, og knyttes mot hverandre hvis de er like eller overlapper – for eksempel om de samme referansene går igjen.
Prosess-mining
Prosess-mining, eller PM som det ofte kalles, er en metode for å analysere hendelseslogger for å identifisere trender og mønstre.
En av de mest populære typene er det som kalles sekvensiell mønsterutvinning, der vi søker å finne sammenhenger mellom forekomster av sekvensielle hendelser, som sporing av handlingsmønstre i en dagligvarebutikk.
Du kan eksempelvis identifisere at kunder kjøper en bestemt samling av produkter sammen til forskjellige tider av året – som en veldig god kaffe, sjokolade og en julekalender. Da kan forretningen lage en pakke med denne typen produkter og forsøke å få enda bedre salg.
Ved å bryte det ned og se på hvilke handlinger som ofte henger sammen og følger hverandre, kan vi lage det som kalles en prosessmodell. Her kan vi se at A pleier å lede til B, men at det eksempelvis forgreiner seg og en går videre enten til C eller D, og så kanskje gjentar D to ganger, og så videre.
Den endelige prosessmodellen kan brukes av en forretning for å undersøke om en bestemt prosess er slik de ønsker den, eller om de kan forbedre den eller gjøre endringer. Kanskje en oppdager eksempelvis at en bestemt prosess ikke flyter så godt som den burde. Så vil en kanskje gjøre endringer, og lage en ny modell. På den måten kan metoden brukes til å finne og forbedre prosesser i en bedrift.