Relasjonsdatabaser
Du husker eksempelet fra forrige del, med kartleggingen av lønnsutvikling og likestilling i IT-bransjen?
Dette var en enkel, liten studie – der Excel var mer enn godt nok som verktøy. Men skulle vi skalert opp dette til å studere et representativt utvalg av hele bransjen, da måtte vi nok tatt i bruk enda kraftigere skyts. Mer spesifikt ville vi typisk brukt en form for relasjonsdatabase.
Du vil bli godt kjent med hva dette er. La oss begynne med et veldig eksempel, for å skjønne nytten og logikken i alt dette.
Filmsamlingen
Si at du er av den gamle skolen, og har en egen filmsamling. Du har både DVD-er, Blu-Ray og 4K-filmer – til og med noen gamle VHS-er i boden! – samt filmer du har kjøpt og eier digitalt på ulike tjenester.
Nå er ikke regnearket lenger nok: For å få oversikt over samlingen trenger du en database!
Hvorfor og hvordan skulle du ordnet det, spør du?
Denne måten å strukturere dataene på – der dataene og lagringsstrukturen så å si er løsrevet fra hverandre – gjør at en enkelt kan gjøre endringer og oppdateringer uten at det blir krøll og følgefeil.
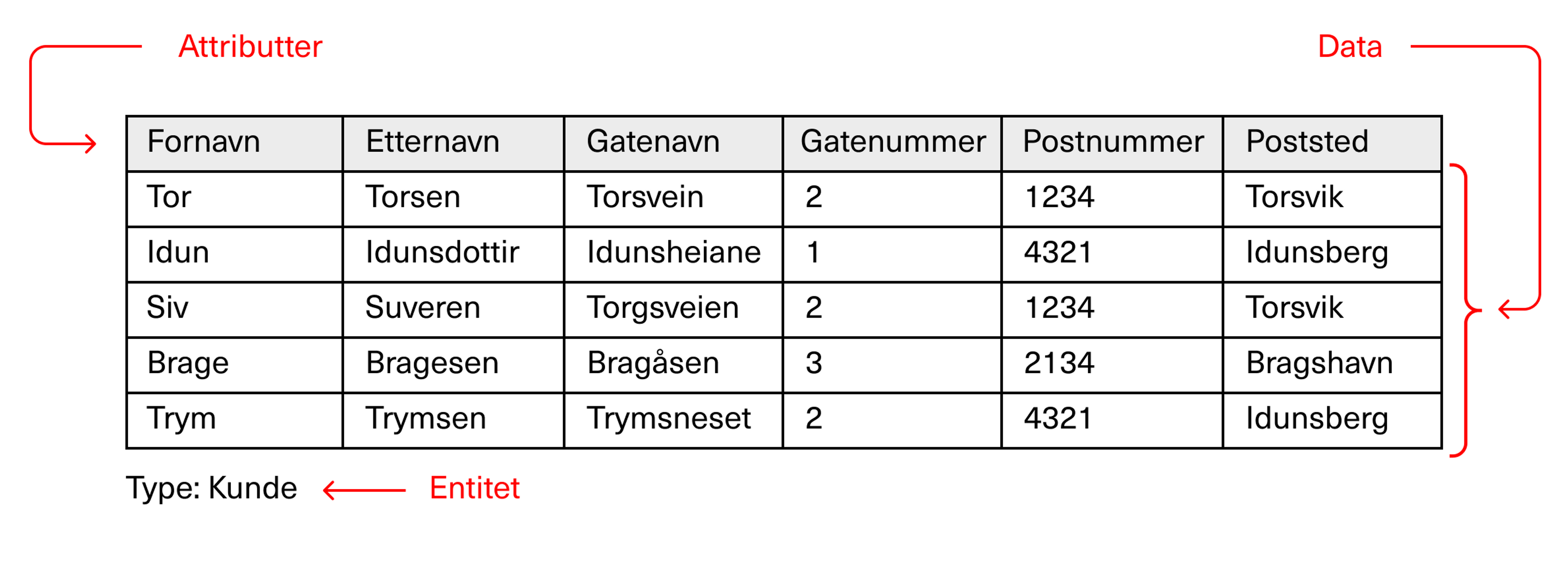
Entiteter og attributter
I en relasjonsdatabase grupperes data i det vi kaller entiteter. Entiteter er logiske enheter av data; tenk på det som «noe som finnes» (enten fysisk, digitalt, konseptuelt eller hva det skulle være), som du samler data om. For eksempel «kunder», «behandlinger» eller «dataprogrammer».
Når du jobber i regneark, vil entiteten typisk være det du kaller selve arket eller fanen.
Attributter er egenskaper som kan knyttes til en entitet. Hvis for eksempel entiteten er en liste over kunder i en bedrift, vil attributtene være de tingene som det er ønskelig å vite om vedkommende. Det kan være fornavn, etternavn og kjønn, og kanskje i noen tilfeller – som innen bank og forsikring – også detaljer som alder og inntekt.
I regnearket vil attributtene typisk være navnet på hver kolonne.
Ingen av disse er altså selve dataene – men heller måten dataene er strukturert på. Dataene får vi når vi fyller inn entitetens attributter med konkrete verdier.
I dette regnearket vil altså selve arket være entiteten (kunder); her finnes det kolonner for ulike attributter (som fornavn og etternavn), og under disse kan dataene føres inn (Trym Trymsen og Siv Suveren).
Et annet eksempel på en entitet kan være bøker, registrert med attributter som forfatters navn, navn på verk, forlag, ISBN, detaljer om opplag, med mer. Eller entiteten kan være resirkuleringspunkter, med attributter som type, lokasjon, kapasitet og vekt. Kort sagt kan det være hva som helst!
Redundans: Når vi lagrer samme ting mange ganger
Hvis vi ser litt nærmere på regnearket med kundedataene, merker vi oss noen praktiske og logiske ting som det er lett for oss mennesker å forstå, men som kan skape trøbbel når dette leses av en datamaskin.
Vi ser for eksempel at Tor og Siv har samme adresse, og at Idun og Trym bor på samme poststed.
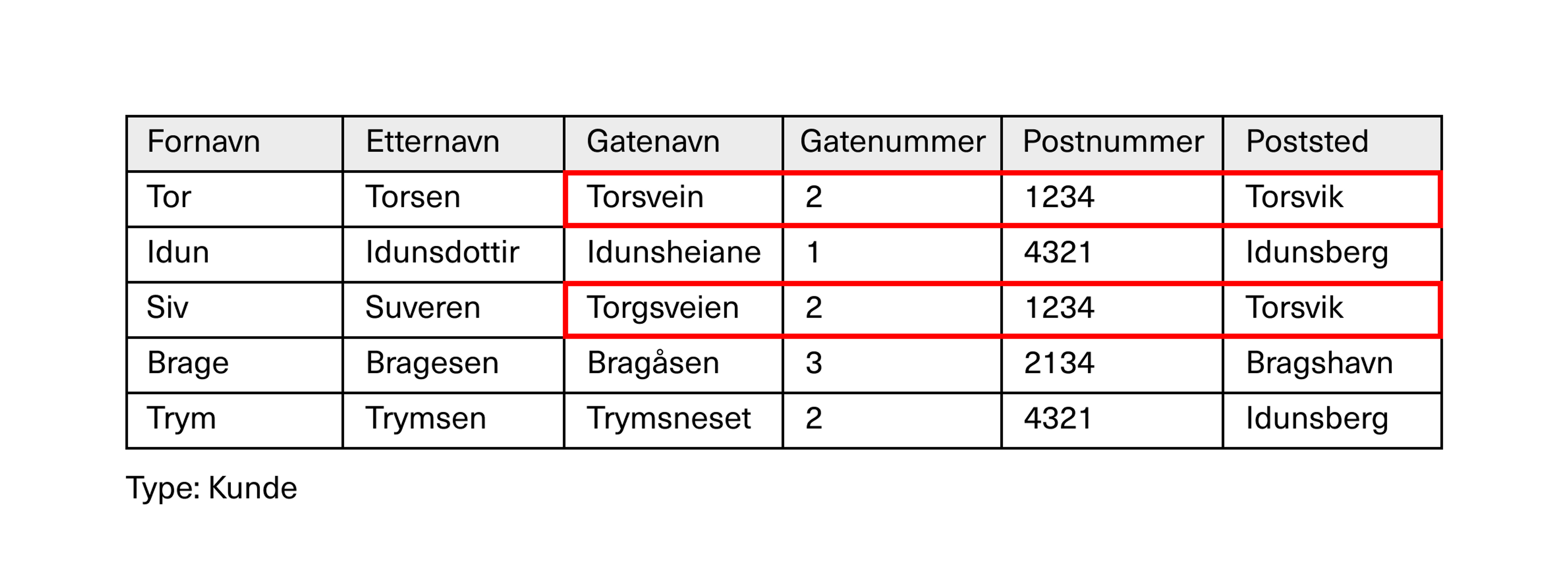
Slik regnearket er strukturert, må full adresse lagres for både Tor og Siv. Det er også slik at postnummer og poststed må repeteres i databasen for alle kunder som bor på samme sted. Dette kalles redundans.
Redundans er problematisk av to grunner. For det første er det lite effektivt med tanke på oppbevaring av selve dataene – gjerne i datasentre bestående av mange harddisker, som krever plass, energi, og kjøling.
For det andre er slik dobbeltlagring en kilde til feil i databaser, gitt at systemer må være på plass for å tilse at endringer i en oppføring umiddelbart reflekteres i alle andre relevante oppføringer – som hvis for eksempel Idunsberg skifter navn som følge av en administrativ endring som en kommunesammenslåing, og dette skal oppdateres for alle kunder bosatt på stedet.
Å tilse at veldig mange elementer endres riktig og samtidig, er mer komplekst enn å gjøre en enkelt endring – og derfor øker muligheten for feil.
Dessuten er det slik at mennesker kan flytte – vi bor ikke nødvendigvis på samme sted hele livet.
I en relasjonsdatabase vil vi derfor skille kunde og adresse fra hverandre – både slik at kunder kan bytte adresse, og slik at vi kan ha flere kunder som bor på samme adresse.
Innsikt
Datahistorikk
En annen fordel med å bruke relasjonsdatabaser – til forskjell fra for eksempel et regneark – er at det blir enklere å ta vare på historiske data.
Si at for eksempel Brage Bragesen er lagret med en adresse i databasen, og får et nytt bad levert på denne adressen. Senere flytter imidlertid Brage til en ny adresse, hvor han anvender samme leverandør for et nytt bad. Leverandøren oppdaterer dermed adressen hans. Men da vet de ikke lenger hvor de leverte det forrige badet!
Ved å skille logiske datablokker som personer og adresser, kan vi relasjonsdatabaser derimot gjøre knytninger mellom en bestilling og en historisk adresse – selv om kunden skulle endre detaljene sine.
Entitet, attributt og relasjon
La oss gå tilbake til entiteten i relasjonsdatabasen vår – for siste gang i regneark-versjon.
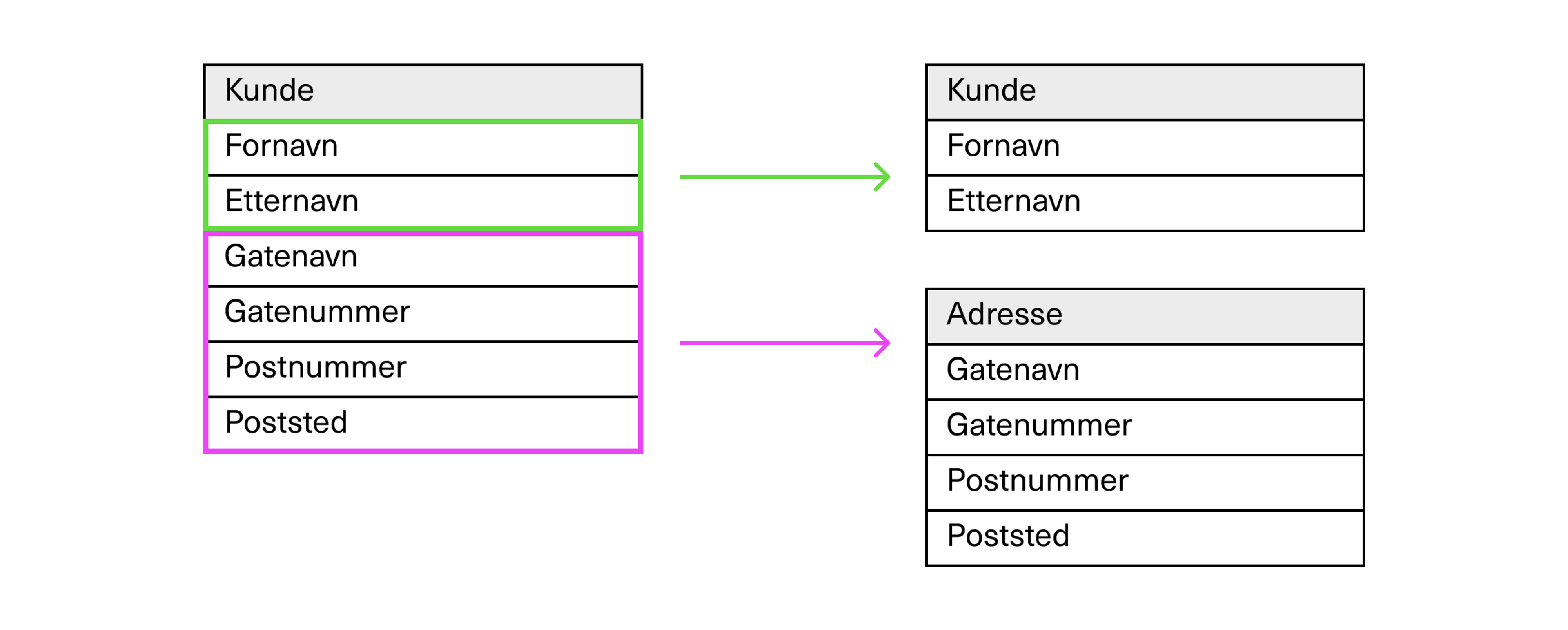
Vi vil nå oppløse den opprinnelige kundeentiteten, og skille adressen fra denne. Den ene entiteten inneholder da kunden registrert med sitt fornavn og etternavn, og den andre inneholder adresser.
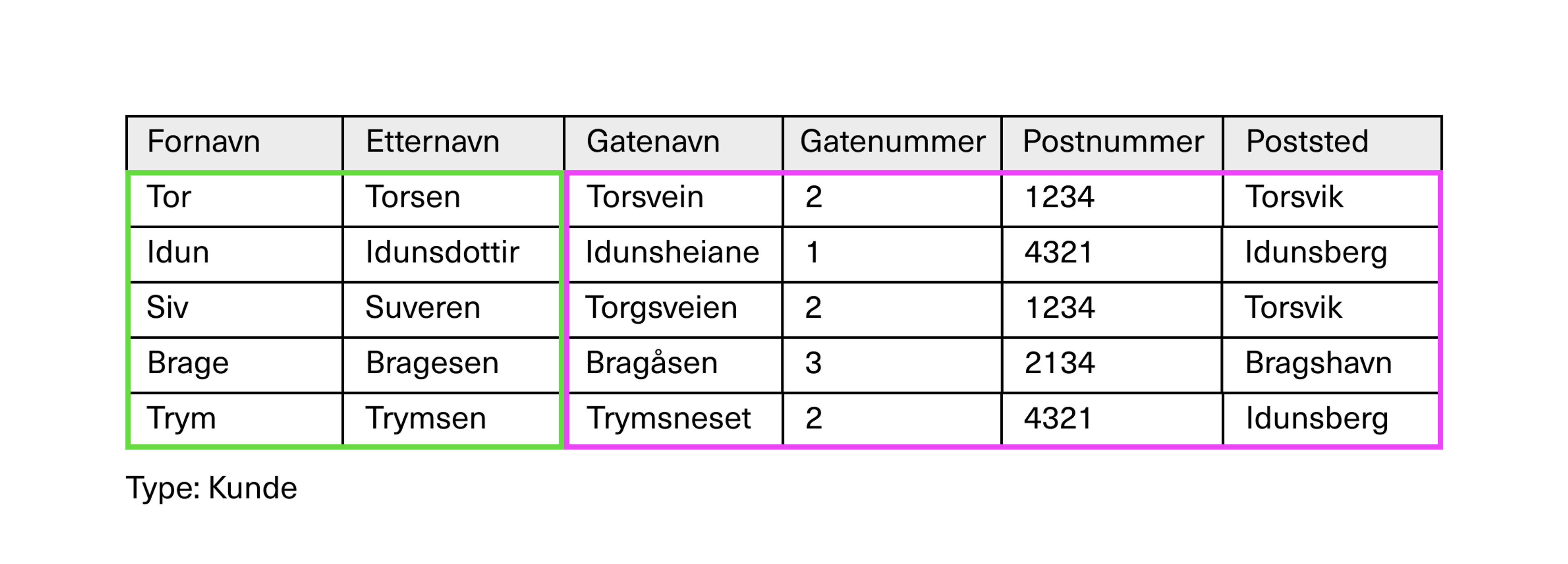
Adresser kan i stedet knyttes til kunder med en relasjon. Endringer gjort for en adresse vil da reflekteres for alle kunder som har denne adressen, selv om vi bare endrer adressen ett enkelt sted.
Dette er en del av prinsippene som ligger i relasjonsdatabasemodellering, noe vi kaller EAR-modellering (for entitet, attributt og relasjon).
Det er imidlertid fremdeles flere gater som deler samme poststed. Så for å unngå å måtte registrere det samme postnummeret og det samme poststedet på nytt for hver eneste gateadresse som finnes på samme sted, kan vi skille dette fra hverandre også. Vi skiller ut nok en ny entitet:

Dette er gode prinsipper for hvordan man jobber med relasjonsdatabaser. Kunder bor på adresser, og adresser tilhører poststeder.
Så langt har vi snakket om entiteter og attributter, samt data som lagres i relasjonsdatabaser. Foreløpig forteller imidlertid ikke databasen vår noen ting om hvem som bor på hvilken adresse, eller hvilken adresse som tilhører hvilket poststed.
Slike oppslag gjøres gjennom relasjoner mellom entitetene, der attributtene tjener som nøkler til oppslag. Det er denne strukturen med relasjoner og nøkler som har gitt navnet relasjonsdatabaser.
Hva som menes med relasjoner, og hvordan dette fungerer, skal vi gå videre inn på i neste emne.